ISUNARABE合同演習2026 に Codex 一本で参戦した
ISUNARABE合同演習2026 に Codex 一本で参戦して、Rust → Go 移行から DB 再設計、ベンチ自動化まで丸投げで進めた話。
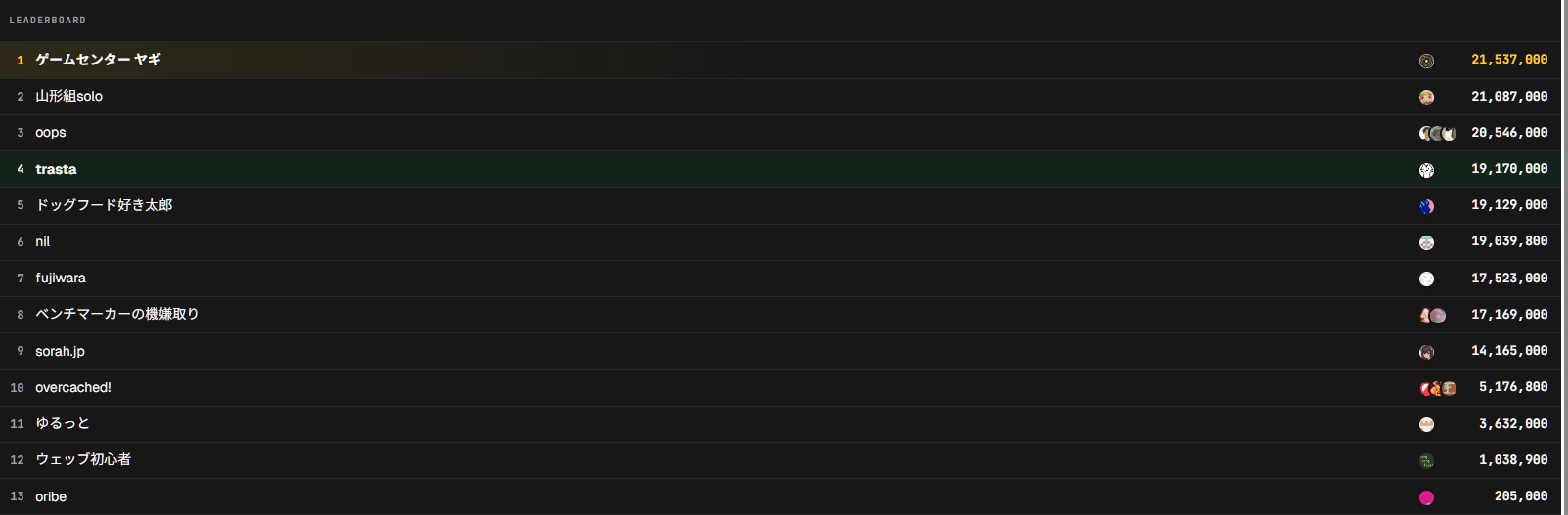
isunarabe での ISUCON の合同演習に、Codex 一本で参戦して 4 位フィニッシュでした。100% Codex に丸投げで1行もコードを読まずにフィニッシュしました。何を投げて Codex がどう返してきたかを、残しておきます。
環境はインスタンスに直接 Codex をインストールして、Codex app の SSH 経由で繋いで編集する構成です。webapp はもともと Rust 実装で、コンテスト中に Go へ書き換える方針で進めました。
リポジトリ
コンテストは終わったので、参戦リポジトリを public にしました。
trasta298/nrb2026
isunarabe 2026 の参戦リポジトリ。Go 実装と Codex 用 skill 群が入っています。
github.com
.codex/skills/ の下にある nrb-bench-log-analysis (ログの集計と分析) と nrb-benchmark-loop (ポータル経由でベンチを回す改善ループ) は、事前に用意していたものではなく、コンテスト中に必要になったタイミングで Codex に作らせた skill です。
ざっくりの方針
webapp はもともと Rust 実装ですが、ベンチを回すたびに build 待ちが発生するのが嫌だったので、開幕で Go に書き換えてしまいました。別言語への移植自体は今の時代ハードルが低いので、最初にまとめて済ませるのが楽です。そのうえで AGENTS.md のルールを 2 つだけ固めて、
- マニュアル仕様 > Rust 参考実装(Rust が落ちていたり実装が変でも、マニュアルに明記があるならマニュアルを優先する)
- 性能最優先・後方互換性ゼロ(競技なので攻めていい)
をベースに走らせています。これは AGENTS.md にもそのまま書いておいてもらいました。
まずは全エンドポイント分析
最初に投げたのはこれです。
webappは今rust実装ですが、golangに実装を移行しようと考えています。
まず、今の全エンドポイントに対して、どういう役割のエンドポイントで、どういうデータが飛んでくるのかについて分析して、mdにまとめてほしいです。また、e2eテストスクリプトも書いてほしいかも
作業を行う上で、subagentをたくさん立ち上げて並列で分析してください。また、sqlのdb構造はマニュアルにもある通り変更可能なので、db構造に縛られない形で書いてほしいです返ってきたのがこれ。
完了です。5 本の subagent 分析を取り込んで、DB 構造に縛られない HTTP 契約としてまとめました。
作成/変更したもの:
- webapp-api-contract.md
全エンドポイントの役割、auth、request/response、validation、状態遷移、通知、課金、与信、画像/ETag、Go 移行で守るべき不変条件を整理しました。
- e2e_smoke.py
`BASE_URL` 指定で動く API smoke test です。`initialize`、user 作成、saved search、campaign 作成、画像/ETag、join、通知 dedupe、charges、credit limit、軽い並行 join probe まで見ます。
- .gitignore
`webapp/e2e_smoke.py` が repo 上で ignored にならないように unignore を追加しました。subagent 5 本並列で投げて分析を一発で取り込んでくれます。いきなり書き換えるよりも、ある程度指針をまとめさせたほうがうまくいきそうという普段遣いからの謎の経験則でやってます。
DB 設計を subagent 同士で議論させる
エンドポイントの輪郭が見えたので、次は DB 構造を考えてもらいました。「正しいレスポンスさえ返せば攻めた実装してもいい」「後方互換性は一切考えなくていい」と方針を伝えて、subagent をたくさん立ち上げて議論させます。
返ってきた db-design.md の大枠はこんな感じでした。
- 正規化より、ベンチ hot path に合わせた wide/summary table に寄せる
- `users.open_credit_used` を持ち、`GET /api/me` は 1 row lookup
- `campaigns.current_count/is_open/active_at/tag_mask/tags_json/participants_json` を持ち、一覧/詳細の COUNT/JOIN を消す
- 内部 ID は `BIGINT UNSIGNED`、API UUID は `public_id BINARY(16)`
- tag は `BIGINT UNSIGNED tag_mask`
- `campaign_participants PRIMARY KEY(campaign_id,user_id)` で二重参加防止
- `charges UNIQUE(campaign_id,user_id)` で二重課金防止
- `notification_outbox PRIMARY KEY(campaign_id,user_id)` で重複通知防止
- 画像は hot な `campaigns` から分離し、metadata DB + filesystem/OS page cache 方針
- `join` は campaign row `FOR UPDATE` で直列化し、credit/participants/current_count/charges/outbox を同一 transaction で更新
- `initialize` は 226MB の `seed.sql` parse をやめ、seed artifact + metadata bulk restore へ寄せるこれに対して「攻めた実装でも正しいレスポンスさえ守れていれば OK、その観点でレビューして」と返すと、P1 レビューが 3 件刺さってきました。
**Findings**
[P1] db-design.md の `CHECK` と join 手順が衝突します。最後の join で `current_count = goal_count` に更新した瞬間、まだ `is_open = 1` だと `CHECK ((is_open = 1 ... current_count < goal_count) ...)` に違反します。最終 join では `current_count`, `is_open=0`, `closed_at` を同じ `UPDATE` で反映するか、この CHECK は緩めた方がいいです。
[P1] app memory cache 方針は攻めていて良いですが、commit 後 cache 更新だと、更新失敗・panic・別プロセス/別サーバの stale cache で誤レスポンスになります。特に新規 user 後の auth、closed campaign の list 非表示、`/me` の `credit_used` は即ズレると危険です。単一プロセス前提に寄せるか、mutation 中は app lock で cache と DB を一体更新し、複数台構成なら mutable cache を使わない/同期する設計が必要です。
[P1] 画像 filesystem 方針は速い一方、複数 app server に振るなら correctness の最大リスクです。POST された画像を別ノードの GET が読めないと画像不一致/404 で即死級です。単一 target に固定するならよいですが、複数台で裁くなら shared storage か MySQL BLOB canonical + local read-through cache が安全です。CHECK と join 手順の整合性のあたりは、自分でやってたら絶対見落とすやつです。「攻めた設計を出させる → 攻めた前提でレビューさせる」の二段構えにすると、こういう穴を勝手に潰してくれるのが面白い。
そのまま「外部サービスは使えない前提で、最適化テクニックがほかにないかも調べて、最終レビューして」と投げると、
- P1 相当を1件見つけて修正しました。`notification_outbox` の PK が generation を含まない設計だと、initialize 後に旧 row が残った場合に新走行の通知 insert を潰し得るため、PRIMARY KEY を `(generation, campaign_id, user_id)` に変更しました。
- close 時の deadlock 対策も補強しました。participant row だけでなく、対応する `users` row も昇順 `FOR UPDATE` する方針を追記。initialize を跨いだ outbox 漏れまで気づいてくれて、これも自分では見落としていたポイントでした。
goal フェーズで perf / API / DB / log を回す
ある程度形になったところで、goal コマンドを使って「subagent でレビューさせて、LGTM が出るまで実装を直し続けて」と投げました。
返ってきた成果はこのあたりです。
- 226MB の seed SQL の画像 BLOB import をやめて、
seed.fast.sql約 801KB + 画像ファイル切り出し(manifest の size + sha256 で検証) /api/initializeに outbox barrier を入れて、initialize を跨いだ旧世代の通知漏れを防止campaign_tag_indexで tag filter を index 経路に変更- 画像 cache / seed image を検証してから返す
- method mismatch を 405 に修正
- ベンチ分析用ログの reset/analyze と drop/parse error 可視化を追加
/api/initialize は最終的に約 4.3 秒まで縮みました。go test ./... と e2e_smoke.py --strict-image-cache も PASS まで持っていってくれていて、自分は何もしていません。
ベンチを自動で回したい
ここまで来たら毎回ブラウザでぽちぽちポータルを操作するのが面倒になってきたので、RunBenchmarkJob のリクエストヘッダだけ送って「これで何とかならないかな」と聞いてみました。返ってきたのが、
- ポータル JS の埋め込み proto から
RunBenchmarkJob/GetBenchmarkJobの field を復元 - Python 標準ライブラリだけで grpc-web を叩く
という構成の portal_bench.py です。
書きました: portal_bench.py
ヘッダだけでは足りない部分は、ポータル JS の埋め込み proto から `RunBenchmarkJob` / `GetBenchmarkJob` の message field を復元して、Python 標準ライブラリだけで grpc-web を叩く形にしています。
使い方:
```sh
export ISUNARABE_COOKIE='SESSION=...'
# team_id 確認
/home/isucon/webapp-go/scripts/portal_bench.py --list-teams
# ベンチ実行 + portal log + app JSONL log + analyzer 出力を保存
/home/isucon/webapp-go/scripts/portal_bench.py --team-id 123 --target-index 0
```ベンチループを skill にして回す
最後に、ベンチ自動化と分析をまとめて skill にしてもらいました。.env に cookie と team_id を置いておけば、
/home/isucon/webapp-go/scripts/portal_bench.py --target-index 0で済むようになっています。デフォルトで NRB_ENABLE_LOG=1 が効くようにもしてもらいました。
途中経過
実装をやらせてて、途中経過でおもしろかったところ
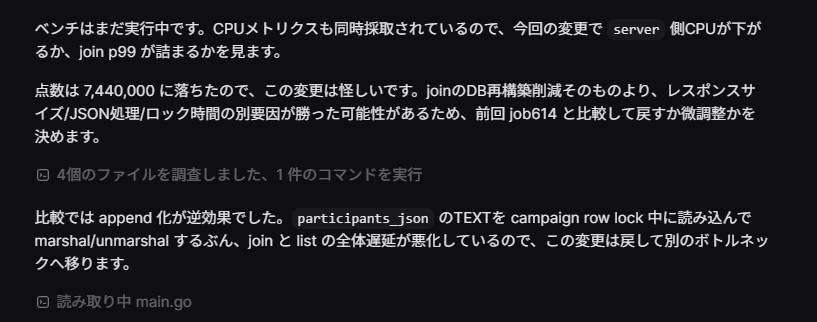
引用するとこんな感じです。
ベンチはまだ実行中です。CPUメトリクスも同時採取されているので、今回の変更で server 側CPUが下がるか、join p99 が詰まるかを見ます。
点数は 7,440,000 に落ちたので、この変更は怪しいです。joinのDB再構築削減そのものより、レスポンスサイズ/JSON処理/ロック時間の別要因が勝った可能性があるため、前回 job614 と比較して戻すか微調整かを決めます。
比較では append 化が逆効果でした。 participants_json のTEXTを campaign row lock 中に読み込んで marshal/unmarshal するぶん、join と list の全体遅延が悪化しているので、この変更は戻して別のボトルネックへ移ります。「数字が落ちた → 該当ファイル読み直し → 原因特定 → revert」を勝手に閉じてくれていました。
participants_json を append 化して TEXT を campaign row lock 中に読み込むのが裏目に出る、みたいなベンチマークをフィードバックとした比較改善が自動で回っていて、ちょっと感動。
定期的にインスタンスが落ちる
ベンチループを回しっぱなしにしていたら、なぜか定期的にインスタンスに接続できなくなって、Codex のループも止まる、という現象に遭遇しました。配信を見ながらやっていたのもあって、しばらく「あれ、進んでないな」とぽちぽちしているうちに結構な時間をロスしました。
AWS 側で何度も再起動する羽目になったので、どうやら再現性がありそうだぞということで原因を調査してもらいました。
これ上のログの直後にインスタンスに接続できなくなりました。一旦aws側で再起動することで入り直したのですが、原因を調査してほしいです返ってきたのがこれです。
修正しました。`analyze_bench_logs.py` を、巨大 JSONL を全件 `list` に積む方式からストリーミング集計方式に変えています。
主な変更です。
- `requests.jsonl` / `events.jsonl` を1行ずつ処理
- slow requests は top N だけ heap で保持
- initialize など event は必要な集計だけ保持
- percentile 用の duration は軽量な `array("Q")` で保持
- ポータル保存後の `app-requests.jsonl` / `app-events.jsonl` も読めるように対応
検証済みです。前回落ちた原因候補だった巨大ログ:
- requests: `1,132,085`
- events: `370,674`
- 合計ログサイズ: 約 `586MB`
に対して analyzer を実行し、結果は:
- 実行時間: `12.75s`
- 最大 RSS: `41MB`
- parse error: `0`要するに、最初に私が「ベンチログ集積 & 分析の仕組みを作って」と投げたときに出てきた analyze_bench_logs.py が、巨大化した JSONL をまるごとメモリに積んでいて、インスタンスを巻き込んで落としていたという話でした。
これくらい書いてるときに指摘してほしかった、しかもインスタンスごと死ぬのは勘弁してほしい。gpt-5.5もまだまだ使えない子ですね。
ストリーミング集計に直してもらって 586MB のログでも 41MB RSS / 12.75s で完走するようになり、ようやくループが止まらなくなりました。
停滞期
ここまでで一通り土台が揃ったので、
ベンチマークループスキルを作成したので、これを回してどこを改善すればいいかsubagentをいっぱいたてて解析してくださいと投げて、ベンチ → 解析 → 修正 → ベンチ、のループを回し続ける状態に入りました。私自身はリアルタイムでは Codex の出力をほとんど読んでおらず、たまに気が向いて覗きに行ったときに「それは違う」と方針を足すくらいでした。
ただ、しばらく回しているとスコアが伸びるどころか下がっていて、同じような小手先修正のあたりをぐるぐる回り続けて抜け出せなくなっていることに気づきました。autonomous なループにベンチスコアだけを評価軸として渡すと、目先で点が動く方向の修正にばかり寄っていって、もっと大きく方針を変えるべきタイミングを逃すんだなぁと思います。
確か1000万点弱くらいで伸び悩んだ気がします。
DB の max_open_conns も 32 → 256 → 96 → 128 と上げ下げを繰り返していたりして、フィードバックは回っているんだけど毎回ノブを行きすぎて戻る、みたいな挙動も挟まっていました。
なので、上からこういうプロンプトを投げ直しました。
スコアは下がってそうなので、スコアが高いときに戻して
一旦過去のISUCONの攻略ブログなども色々探してきて、改善の糸口がないかsubagentをたくさんたてて今の実装も合わせて調査・議論してほしいです。
また、複数台構成にするならどうするのがいいのかも検討してください「過去 ISUCON の攻略ブログも調べて」「複数台構成」みたいな粒の大きい指示を上から落としてあげると、「じゃあ MySQL を捨てて all cache に振り切る」という方針転換をすることになりました。
振り返ってみると、LLMは今のところフィードバックを受けた細かい修正は得意だけど、その分析データを受けての、ISUCON以外ではなかなかやらない大胆な方針転換は苦手そうだなという感じですね。そらそうって感じですが。
なので全体を通して私がやったことは
- 大きい方針を投げる (ISUCONの経験が生きるところ)
- 「攻めていい」「正しいレスポンスさえ返せばいい」みたいな前提を足す (これもISUCON特有なので)
- ぐるぐるしてきたら粒の大きい方針を上から落とす
- たまに様子を覗きに行く(あとで見返したら何やってたか分かるくらいの粒度)
という感じでした。
終了 1 時間前に追試対策を入れる
途中まで完全に忘れていたんですが、コンテスト終了 1 時間前くらいに「あ、追試あるじゃん」と気づいて、慌てて別ターンで対策をさせました。
事前に AGENTS.md でマニュアル参照は徹底させていたし、Codex 自身もマニュアルは読んでいるはずなんですが、追試要件の話には全然触れずに小手先のスコア改善ばかり進めていました。わかっていたことではあるけど、マニュアルに書いてあっても、まだ LLM も普通にすっ飛ばすなぁという感じ。
マニュアルの追試の要件を詳しく読み、今の実装で追試にクリアするかどうかについてsubagentを複数立てて詳しくレビューさせてくださいこれで subagent を並列で立てて要件を洗い出させて、足りない部分を 1 時間で詰めて間に合わせました。最初から AGENTS.md に「マニュアルの不変条件は絶対に見落とすな」みたいに書いておけば防げそうな気もしましたが、経験則それだけではあまり効かなさそうなので、次回も結局は人間側から思い出したタイミングで指摘してやる必要がありそうだなぁと思います。
感想
途中まではシングルの Codex 1 セッションだけで十分回っていたんですが、ループが行き詰まり始めたあたりからは複数インスタンスを立てて、別方針を並列で試させればよかったなぁと思います。1 つのインスタンスを長く回していると、そのコンテキストや方針に引っ張られていきそうなので、違う前提を渡した別インスタンスのほうが脱出しやすかったかもしれません。次に出るときはやってみたいです。
全体的には、あまり知識のない人が使っても途中まではある程度行けるけど、トップ争いするにはまだ人間側から方針を示してやらないと戦えないのかなぁ、という感想でした。ISUCON 強くないので確証はないですが。それでも手の速さは明らかに違いそうなので、もうかなり去年とは別ゲーになっている感はあります。
オチ
裏で Codex に作業を投げている間、Valorant の DFM vs RRQ の配信を見ていたんですが、DFM は負けました。かなしい。