Joining ISUNARABE Joint Practice 2026 with Codex Alone
I joined the ISUNARABE 2026 joint practice using only Codex — pushing it through a Rust-to-Go migration, a DB redesign, and benchmark automation, all hands-off.
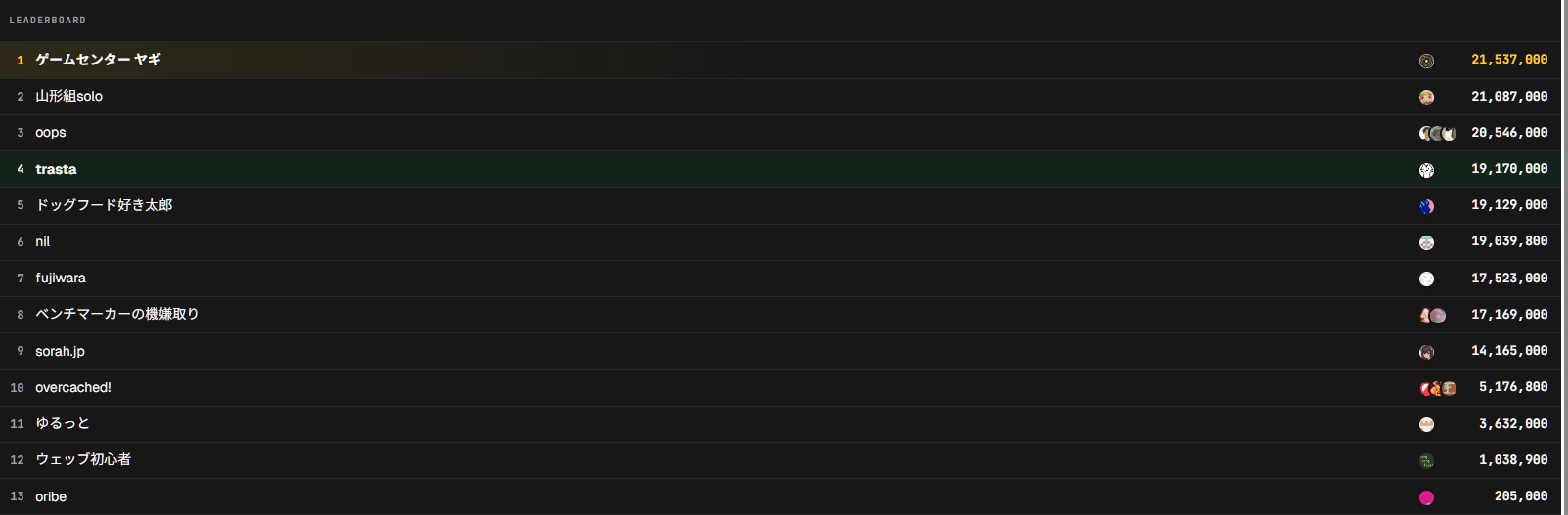
I joined the ISUCON joint practice on isunarabe using only Codex, and finished in 4th place. I went 100% hands-off with Codex and didn't read a single line of code from start to finish. Here's a record of what I threw at it and what came back.
The setup was Codex installed directly on the instance, edited via SSH from the Codex app. The webapp was originally a Rust implementation, and my plan was to rewrite it to Go during the contest.
Repository
The contest is over, so I made the participation repository public.
trasta298/nrb2026
The participation repo for isunarabe 2026. Contains the Go implementation and a set of skills for Codex.
github.com
The two skills under .codex/skills/ — nrb-bench-log-analysis (for log aggregation and analysis) and nrb-benchmark-loop (for the improvement loop that runs benches via the portal) — weren't prepared in advance. I had Codex create them mid-contest as soon as I needed them.
Rough Strategy
The webapp was originally Rust, but I didn't want to wait for a build every time I ran a bench, so I rewrote it to Go right at the start. Porting between languages isn't a big deal these days, so it's easier to just get it out of the way upfront. On top of that, I locked in just two rules in AGENTS.md:
- Manual spec > Rust reference implementation (if the Rust impl is broken or weird, but the manual is explicit, follow the manual)
- Performance first, zero backwards compatibility (it's a competition, so go aggressive)
I had this written straight into AGENTS.md.
Start with a Full Endpoint Analysis
This is the first thing I threw at it.
The webapp is currently a Rust implementation, but I'm thinking about migrating it to Go.
First, I want you to analyze every current endpoint — what role each endpoint plays, what data flows through it — and summarize it in markdown. Maybe also write an e2e test script.
For this work, spin up a lot of subagents and analyze in parallel. Also, the SQL DB schema is changeable per the manual, so write it in a way that isn't tied to the DB structure.What came back:
Done. I integrated the analysis from 5 subagents and summarized it as an HTTP contract that isn't bound to the DB structure.
Created/changed:
- webapp-api-contract.md
Organized every endpoint's role, auth, request/response, validation, state transitions, notifications, charges, credit, image/ETag, and the invariants the Go migration needs to preserve.
- e2e_smoke.py
An API smoke test that runs against a `BASE_URL` you specify. Covers `initialize`, user creation, saved search, campaign creation, image/ETag, join, notification dedupe, charges, credit limit, and a light concurrent-join probe.
- .gitignore
Added an unignore so that `webapp/e2e_smoke.py` doesn't end up ignored in the repo.It runs 5 subagents in parallel and folds the analysis in one shot. Rather than rewriting blindly, getting it to consolidate some kind of plan first usually goes better — that's a vague heuristic I've picked up from daily use.
Make Subagents Argue About the DB Design
Once the endpoint shape was visible, I had it design the DB next. I told it "as long as the response is correct, you can write aggressive implementations" and "you don't have to think about backwards compatibility at all," then spun up a bunch of subagents to argue it out.
The high-level shape of the db-design.md it returned looked like this:
- Lean toward wide/summary tables matching the bench hot path, rather than normalization
- Hold `users.open_credit_used` so that `GET /api/me` is a 1-row lookup
- Hold `campaigns.current_count/is_open/active_at/tag_mask/tags_json/participants_json` so that COUNT/JOIN disappear from list/detail
- Internal IDs are `BIGINT UNSIGNED`; API UUIDs are `public_id BINARY(16)`
- Tags are a `BIGINT UNSIGNED tag_mask`
- `campaign_participants PRIMARY KEY(campaign_id,user_id)` to prevent double-joining
- `charges UNIQUE(campaign_id,user_id)` to prevent double-charging
- `notification_outbox PRIMARY KEY(campaign_id,user_id)` to prevent duplicate notifications
- Separate images from the hot `campaigns` table; metadata in DB + filesystem/OS page cache
- `join` serializes by taking `FOR UPDATE` on the campaign row, and updates credit/participants/current_count/charges/outbox in the same transaction
- `initialize` stops parsing the 226MB `seed.sql` and shifts to a seed artifact + metadata bulk restoreWhen I came back with "aggressive is fine as long as the response stays correct — review it from that angle," three P1 issues came up.
**Findings**
[P1] db-design.md's `CHECK` and the join procedure conflict. The instant the final join updates `current_count = goal_count`, while `is_open = 1` is still set, it violates `CHECK ((is_open = 1 ... current_count < goal_count) ...)`. Either reflect `current_count`, `is_open=0`, and `closed_at` in the same `UPDATE` on the final join, or relax this CHECK.
[P1] The app memory cache approach is aggressive in a good way, but if you update the cache after commit, you'll return wrong responses on update failures, panics, or stale caches on other processes/servers. In particular, auth right after a new user, hiding closed campaigns from the list, and `credit_used` on `/me` — those drift instantly and that's dangerous. Either commit to a single-process assumption, or hold an app lock during mutation so cache and DB update together; if you go multi-node, you need a design where you don't use a mutable cache or you sync it.
[P1] The image filesystem approach is fast but, if you spread to multiple app servers, it's the biggest correctness risk. If a POST'd image can't be read by a GET on a different node, you instantly get image mismatches/404s — kill-level. If you pin to a single target it's fine, but if you serve from multiple machines, shared storage or "MySQL BLOB canonical + local read-through cache" is safer.The consistency between CHECK and the join procedure is exactly the kind of thing I'd absolutely miss if I were doing this myself. The two-step pattern of "have it propose an aggressive design → have it review under aggressive assumptions" is interesting because it patches its own holes for free.
I followed up with "assume external services aren't usable — also research any other optimization techniques and do a final review," and got:
- Found and fixed one P1-equivalent. If `notification_outbox`'s PK doesn't include the generation, and old rows survive after initialize, they can squash notification inserts on a new run, so I changed PRIMARY KEY to `(generation, campaign_id, user_id)`.
- Reinforced the deadlock countermeasure on close. Added a note that not just the participant rows, but also the corresponding `users` rows, should be `FOR UPDATE`'d in ascending order.It even caught the cross-initialize outbox leak — another point I'd missed myself.
Run perf / API / DB / log in the goal Phase
Once it took shape, I used the goal command and threw "have a subagent review, and keep fixing the implementation until it gets LGTM."
The deliverables that came back:
- Stop importing image BLOBs from the 226MB seed SQL; switch to ~801KB
seed.fast.sql+ image files extracted (verified against manifest size + sha256) - Add an outbox barrier in
/api/initializeto prevent leaking notifications from old generations across initialize - Switch tag filter to an index path via
campaign_tag_index - Verify image cache / seed images before serving
- Fix method mismatches to return 405
- Add reset/analyze for bench-analysis logs and surface drop/parse errors
/api/initialize ended up shrinking to about 4.3 seconds. It got go test ./... and e2e_smoke.py --strict-image-cache to PASS as well, and I did nothing.
I Want to Run Benches Automatically
By this point, clicking around the portal in a browser every time was getting annoying, so I sent over the request headers for RunBenchmarkJob and asked "can you do something with this?" What came back was portal_bench.py, structured as:
- Reconstruct the
RunBenchmarkJob/GetBenchmarkJobfields from the proto embedded in the portal JS - Hit grpc-web using only the Python standard library
Wrote it: portal_bench.py.
For the parts where headers alone aren't enough, I reconstructed the `RunBenchmarkJob` / `GetBenchmarkJob` message fields from the proto embedded in the portal JS, and hit grpc-web using only the Python standard library.
Usage:
```sh
export ISUNARABE_COOKIE='SESSION=...'
# check team_id
/home/isucon/webapp-go/scripts/portal_bench.py --list-teams
# run bench + save portal log + app JSONL log + analyzer output
/home/isucon/webapp-go/scripts/portal_bench.py --team-id 123 --target-index 0
```Wrap the Bench Loop in a Skill
Finally, I had it bundle the bench automation and analysis into a skill. With cookie and team_id sitting in .env,
/home/isucon/webapp-go/scripts/portal_bench.py --target-index 0is enough now. I also had it default NRB_ENABLE_LOG=1 to on.
A Snapshot Mid-run
While I was letting it implement things, here's a moment that was fun to watch.
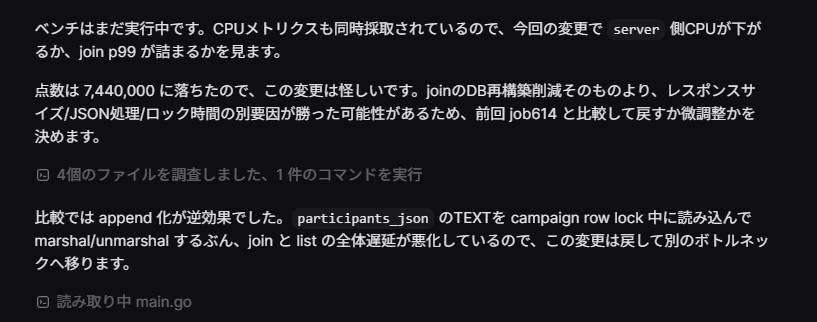
The quote, roughly:
The bench is still running. CPU metrics are being collected at the same time, so I'll watch whether server-side CPU drops with this change, or whether join p99 backs up.
The score dropped to 7,440,000, so this change is suspect. Rather than the join DB-rebuild reduction itself, another factor — response size / JSON processing / lock time — may have outweighed it, so I'll compare against the previous job614 and decide between a revert and a tweak.
In the comparison, going to append was counterproductive. Reading the participants_json TEXT and marshal/unmarshal'ing it under the campaign row lock made join and list overall latency worse, so I'll revert this change and move to a different bottleneck.It was closing the loop on its own: "number dropped → re-read the relevant files → identify cause → revert."
The fact that benchmark-feedback comparison-driven improvement was running automatically — including catching that switching participants_json to append-mode was counterproductive because it forced TEXT reads under the campaign row lock — was honestly kind of moving.
The Instance Keeps Going Down
While I was running the bench loop unattended, I kept hitting this bizarre issue where the instance would periodically become unreachable, and the Codex loop would stall with it. I was streaming this on Twitch, so I lost a fair amount of time poking around going "huh, it's not progressing" before noticing.
After I had to reboot the instance from the AWS side multiple times, it was clearly reproducible, so I had Codex investigate.
Right after the log above, the instance became unreachable. I rebooted from AWS and got back in, but I want you to investigate the cause.The reply:
Fixed it. I changed `analyze_bench_logs.py` from a "stuff the entire huge JSONL into a `list`" approach to a streaming aggregation approach.
Main changes:
- Process `requests.jsonl` / `events.jsonl` line by line
- Hold only top-N slow requests in a heap
- For events like initialize, hold only the aggregations actually needed
- Hold percentile durations in a lightweight `array("Q")`
- Also support `app-requests.jsonl` / `app-events.jsonl` saved by the portal
Verified. Against the huge logs that were the prime suspect for last time's crash:
- requests: `1,132,085`
- events: `370,674`
- combined log size: about `586MB`
I ran the analyzer and got:
- runtime: `12.75s`
- max RSS: `41MB`
- parse errors: `0`The short version: the analyze_bench_logs.py it had originally produced when I first asked for "a system to collect and analyze bench logs" was loading the entire bloated JSONL into memory and taking the instance down with it.
I would've appreciated a heads-up at the time of writing that, and please don't kill the entire instance. gpt-5.5 is still not quite there.
After it switched to streaming aggregation, it could process 586MB of logs in 41MB RSS / 12.75s, and the loop finally stopped dying.
The Plateau
With the foundation in place, I sent
Now that the benchmark loop skill is built, I want you to run it and have a bunch of subagents analyze where to improve.and let it spin into a state of continuously running bench → analyze → fix → bench. I barely read any of Codex's real-time output myself; I'd just occasionally peek in and add direction with "no, that's wrong" if something felt off.
After a while, though, the score wasn't climbing — it was actually dropping, with the loop going in circles around the same kind of small tweaks and unable to break out. When you hand an autonomous loop nothing but the bench score as its evaluation axis, it leans toward fixes that move the number in the immediate term and misses the moments when a bigger pivot is needed. I think we plateaued somewhere just under 10 million points.
I also caught it bouncing the DB's max_open_conns between 32 → 256 → 96 → 128 — the feedback loop is working, but it overshoots and walks back every time.
So I dropped this prompt from above:
The score seems to be dropping, so revert to a high-scoring point.
For now, dig up past ISUCON write-ups and use them — spin up a bunch of subagents to investigate and discuss together with the current implementation, looking for clues for improvement.
Also consider how a multi-node setup would work.When you drop coarse-grained instructions from above like "go look at past ISUCON writeups" and "multi-node setup," it shifted to a different policy entirely: "drop MySQL and go all-in on cache." Looking back, LLMs are good at fine-grained edits driven by feedback right now, but the kind of bold pivot you almost never make outside of ISUCON — informed by that analysis data — seems hard for them. Which, fair enough.
So across the whole thing, what I personally did was:
- Drop the big-picture direction (where ISUCON experience helps)
- Add premises like "you can be aggressive" and "as long as the response is correct" (also ISUCON-specific)
- When it's going in circles, drop a coarse-grained policy from above
- Occasionally peek in (granular enough that I could reconstruct what it had been doing later)
And that was about it.
Bolt-on Re-test Countermeasures with 1 Hour Left
I'd completely forgotten about it for most of the contest, but with about an hour to go I realized "oh wait, there's a re-test" and rushed to handle it in a separate turn.
I had AGENTS.md enforcing manual reference, and Codex itself should be reading the manual, but it never touched the re-test requirements at all, just kept chasing immediate score improvements. I knew this could happen, but even when something is in the manual, LLMs will still skip right past it.
Read the re-test requirements in the manual carefully. Spin up multiple subagents and review in detail whether the current implementation passes the re-test.This had subagents enumerate the requirements in parallel, and I crammed in the missing pieces in an hour to make it. I half-thought I could've prevented this by writing something like "never miss invariants in the manual" in AGENTS.md from the start, but heuristics alone don't seem to do enough, so I expect even next time I'll need to remember from the human side and prompt it.
Reflections
Through most of this, a single Codex session was enough, but once the loop started getting stuck, I should have stood up multiple instances and tested different policies in parallel. Running one instance for a long time tends to drag along its context and direction, so a separate instance with a different premise might escape easier. I'll try this next time.
Overall: even someone without much knowledge can get pretty far this way, but to fight at the top, the human still has to set the direction. I'm not strong at ISUCON so I can't be sure, but the speed of execution is clearly different — it already feels like a different game from last year.
Punchline
While Codex was working in the background, I was watching the DFM vs RRQ Valorant stream. DFM lost. Sad.